嵌入式语音识别和边缘侧语音人工智能解决方案商Sensory,近期宣布推出可以更好的理解和识别儿童独特的语音特征的(linguistic pattern)的可客制化的全新语音识别模型。Sensory新的面向儿童语音识别市场的新算法和模型的推出,将为合作伙伴的面向儿童市场的诸如玩具,穿戴,APP等的语音交互产品,带来更高水准的语音识别率。

全新的模型和算法专为儿童的语音特征而设计,支持Sensory的TrulyHandsfree关键词命中语音识别算法和TrulyNatural大词汇量连续语音识别算法。得益于该技术的进步,面向儿童市场的APP,玩具,穿戴和其他教育类产品的合作伙伴,可为其产品的语音交互界面带来无与伦比的识别准确率和隐私保护性。
儿童语音与成人相比有非常大的不同,因此本身识别儿童的语音是相当具备挑战性,再加上训练数据的缺乏,更加增加了其难度。为了更好的理解和识别儿童的语音,得益于Sensory数十年对儿童语音数据的收集和分析,新推出的语音模型和算法经测试显示,对比成人语音识别模型,其词识别错误率(word error rate)降低达33%。
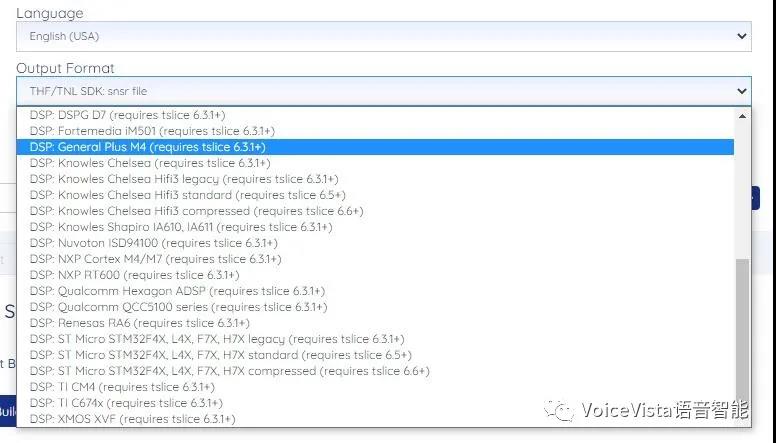
GeneralPlus(https://www.generalplus.com/)为全球的语音和玩具市场提供数百万的芯片,已经在其数款芯片中集成和支持Sensory的儿童语音识别算法和模型。
合作伙伴和开发者可以通过Sensory的VoiceHub – 开放注册的免费离线语音模型生成工具门户, http://www.sensory.com/voicehub – 自主和免费的生成适配支持不同DSP/MCU硬件所需格式的,面向儿童英语市场的所需语音模型。
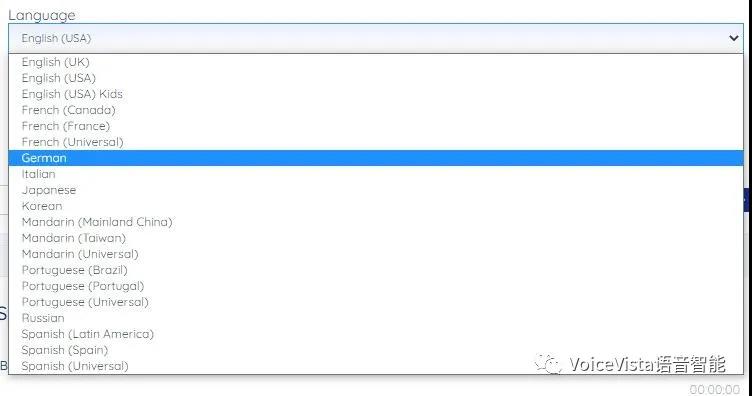
同时适配和支持包括GeneralPlus芯片在内的最广泛的嵌入式硬件平台。
Sensory的嵌入式人工智能技术已经广泛的应用于包括手机,车载,穿戴,玩具,IoT,医疗,家用电器等在内的广泛的需要语音人机交互的设备场景中,其嵌入式人工智能技术组合包括TrulyHandsfree语音控制,TrulySecure生物识别和验证,TrulyNatural自然语言识别等。更详细的信息请访问 – www.sensory.com。