乐鑫科技 AI 实验室自主研发的声学前端 (Audio Front-End, AFE) 算法已通过亚马逊 Alexa 内置设备的 Software Audio Front-End 认证。长久以来,乐鑫不仅致力于为 AIoT 领域打造领先的无线连接方案,并已向提供高性能的边缘机器学习迈出了坚实的一步。
乐鑫 AFE 算法可基于集成了 AI 和 DSP 加速的 ESP32-S3 SoC 进行声学前端处理,使用户获得高质量且稳定的音频数据,为构建智能语音和 Alexa 内置设备提供了一个性能卓越且高性价比的解决方案。乐鑫后续推出的其他集成 AI 和 DSP 加速的 SoC 也将为 AFE 算法提供硬件支持。
语音用户界面 (VUI, Voice-User Interface) 作为一种人与智能设备交互的自然形式,在 AIoT 领域得到了迅速的发展和普及,也随之提升了用户对其性能的更多期待。目前,智能语音设备需要在远场噪声环境中,甚至在播放音频的同时,仍能实现准确的语音唤醒和识别。乐鑫的人工智能实验室研发了一套用于解决这些需求的算法框架,包括多通道声学回声消除 (AEC, Acoustic Echo Cancelation)、盲源分离 (BSS, Blind Source Separation)、语音活动检测和噪声抑制 (NS, Noise Suppression)。算法在两个麦克风间距只有 2 cm 时也能稳定工作。它们先向语音用户界面提供过滤后的音频信号,然后通过离/在线的方式对音频进行有效处理。
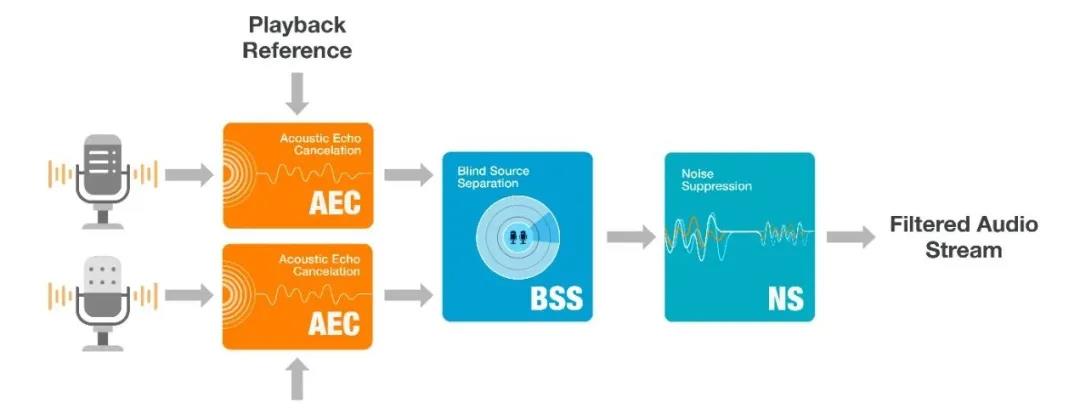
乐鑫 AFE 算法基于 ESP32-S3 的 AI 和 DSP 加速器进行了优化,仅消耗 12-20% CPU 空间和 460 KB 存储空间(220 KB 内存和 240 KB 外部存储),能够为运行在同一 SoC 上的其他应用程序保留充足的资源空间。
乐鑫为客户产品提供声学设计支持,从而帮助客户更专注于创造产品的核心价值。您可以在 GitHub 上了解更多关于乐鑫 AFE 算法的信息。如果您有任何问题或建议,请联系乐鑫的客户支持团队,我们将竭诚为您服务。




